
티스토리 뷰
📌 리스트 (배열) using JAVA
📒 기본적인 배열의 선언
// 배열의 선언
int[] arr;
int arr[];
// 배열의 생성후 초기화 ( 주소가 할당된다. )
int[] arr = new int[8];
String s_arr = new String[8];new를 해주지않으면 해당 배열은 null값을 가지며, null값을 가진 상태에서 배열을 활용하려고 하면
NullPointerException이 발생한다. NullPointerException이 뜨면 1차적으로 배열의 index값이 제대로 있는지 확인하자.
배열의 초기화
// 특정값으로 초기화
int[] arr = {1,2,3,4,5};
// 모두 같은 값으로 초기화 (for문으로도 가능)
Arrays.fill(arr,1);
// foreach문을 통한 배열출력
for (int i:i_array) {
system.out.print(i);
}
배열을 쓸때, 임의 위치에 있는 원소를 변경/확인, 그리고 처음이나 마지막에 있는 원소를 추가하거나 제거 하는데에는 O(1) 이라는 짧은 시간이 걸리지만, 임의의 위치에 원소를 추가하는 경우에는 이미 있던 원소들을 모두 밀어내야 하므로 O(N) 이라는 시간이 걸리게 된다.
ArrayList는 java.util.ArrayList에 포함되어 있으므로 먼저 java.util.ArrayList import를 한다.
import java.util.ArrayList;ArrayList를 사용하려면 먼저 ArrayList 객체를 만들어야 한다.
ArrayList<Integer> numbers = new ArrayList<>();추가를 위한 add는 배열의 뒤에 데이터를 더한다.
numbers.add(10);
numbers.add(20);
numbers.add(30);
numbers.add(40);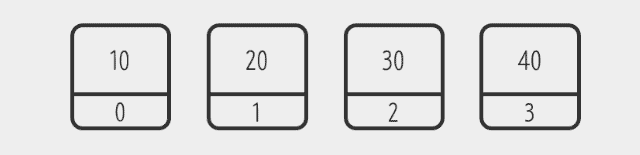
1번인덱스에 50을 넣는 다음과 같은 코드도 20을 빼고 50을 넣는게 아닌 20을 뒤로 밀어내고 50을 넣는다.
numbers.add(1, 50);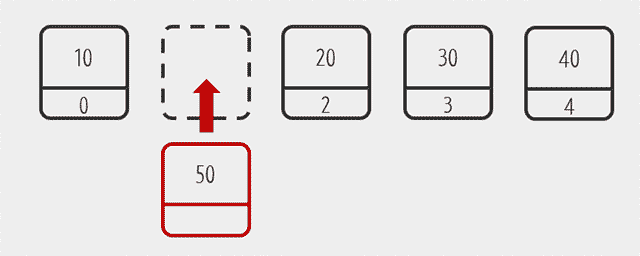
삭제를 위한 remove 메소드도 마찬가지로 삭제하고, 빈자리는 옆에서 땡겨온다.
numbers.remove(2);
특정 인덱스에 위치한 엘리먼트를 가져올때는 get을 사용한다.
이때 내부에서는 배열을 사용하기때문에 ArrayList는 매우 빠르게 엘리먼트를 가져온다.
numbers.get(2);
ArrayList를 탐색할때 는 Iterator를 사용한다.
Iterator it<Integer> = numbers.iterator();// Iterator를 이용한방법
while(it.hasNext()){
System.out.println(it.next());
}
// foreach문을 이용한 방법
for(int value : numbers){
System.out.println(value);
}이 외에도 몇개의 엘리먼트가 있는 지확인하는 size() 메소드와 리스트안에 있는 값을 확인하는 contains() , 목록에 원소가 있는지 확인하는 isEmpey() 객체 매개변수의 인덱스를 확인하는 indexOf() ArrayList에 ArrayList를 추가하는 addAll()등이 있다.
📌 스택 ( Stack )
스택, Last In First Out 한쪽 끝에서만 원소를 넣거나 뺄 수 있는 자료구조이다.
큐, 덱도 마찬가지로 특정위치에서만 원소를 넣거나 뺄 수 있고 이러한 자료구조들을 Restricted Structure라고 부른다.

스택은 수식의 괄호 쌍, 전위/중위/후위 표기법, DFS등에 자주 쓰인다.
📌 큐 ( Queue )
Fist In First out -> FIFO로 많이 불린다.
한쪽 끝에서 원소를 넣고 반대쪽 끝에서 원소를 뺄수있는 자료구조이다.
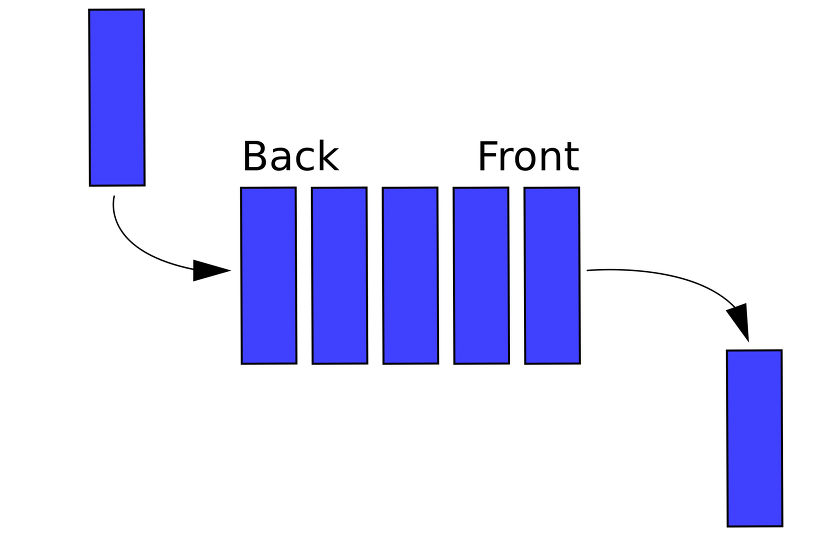
BFS에서 자주 사용된다.
📌 해쉬 ( HASH )
해쉬함수는 임의의 길이의 데이터를 고정된 길이의 데이터로 대응시키는 함수이다.
예를들어 1358 3549 5488 5466 라는 카드번호를 >> 1358로 해쉬화 하는것이다.
그런데 이방식에는 Collision이라는 큰 문제가 있다.
이문제를 해결하기위한 두가지 방법이 있는데, Open Addressing과 Chaining이다.
📒 Open Addressing

이러한 문제를 해결하기위해 1358이 겹치면 1359에 한칸띄어 저장하는 방법인 Linear probing이라는 방법이다.
이외에도 1, 3, 5, ... 칸씩 뛰어서 처음의 칸으로부터 1의 제곱, 2의 제곱, 3의 제곱 떨어진 칸을 보는 Quadratic probing, 그리고 또 다른 해쉬 함수를 두어 그 결과만큼 뛰는 Double hashing 등의 방식이 있다.
📒 Chaining
Chaining은 해쉬 테이블에서 각 인덱스에 원소 1개만을 담는 것이 아니라 Linked List 구조로 여러 원소를 담고 있는 방식을 의미한다. 꼭 Linked List일 필요는 없고 동적배열도 상관없다.
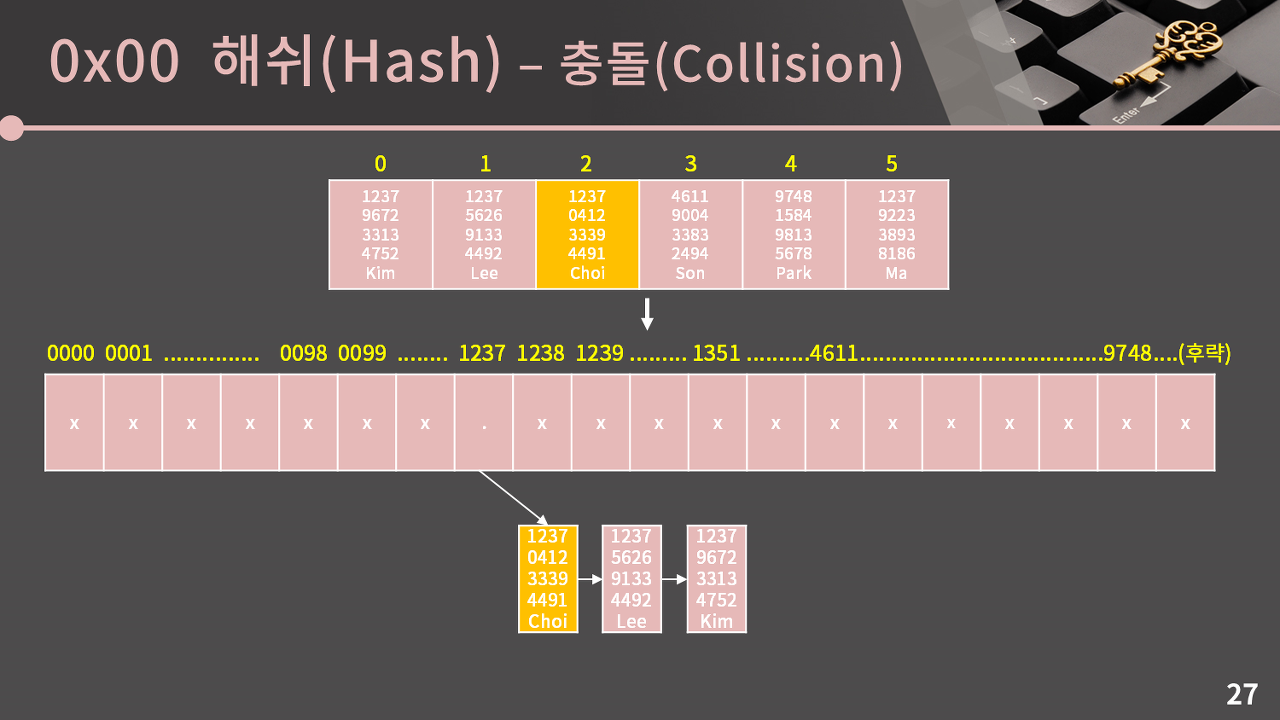
1237이 겹치는 경우에, 맨뒤에 붙여도 잘 동작하지만, 맨 뒤에 두면 1237번지에 있는 노드의 갯수만큼 이동한 뒤에 새로운 노드를 부착해야 하므로 시간복잡도에서 손해를 본다. 따라서 앞에 붙여준다.
해쉬의 삽입, 삭제, 검색 모두 시간복잡도는 이론적으로 O(1) 이지만,
충돌이 발생함으로서 실제 시간복잡도는 더 나쁠 수 있다.
같이 풀어볼 문제 : https://programmers.co.kr/learn/courses/30/lessons/42587
'ALGORITHM' 카테고리의 다른 글
| [ 알고리즘 ] 2. 연결리스트 (0) | 2020.03.26 |
|---|---|
| [ 알고리즘 ] 1. 배열 (0) | 2020.03.23 |
| [ 4주차 ] 동적 계획법 (0) | 2019.12.01 |
| [ 1주차 ] 완전탐색, 정렬, 문자열 (0) | 2019.11.10 |
- Total
- Today
- Yesterday
- 파이썬
- 의대 신경학 강의
- 백준
- query
- conTeXt
- gunicorn
- 소프트웨어 장인
- 팰린드롬수
- sql lite
- go
- for-else
- go context
- dfs
- Two Scoops of Django
- 문자열 뒤집기
- 방금그곡
- leetcode
- 독후감
- Python
- taggit
- 프로그래머스
- stdout
- django
- ManyToMany
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |